







 超级会员免费看
超级会员免费看
MapReduce 数据本地化
数据本地化是指把计算移动到数据所在节点上进行执行的过程,也就是通常所说的 “移动计算而不是移动数据”。移动计算比移动数据具有更大的优势,它可以降低网络开销,增加系统的整体吞吐量。
数据本地化的概念
让我们来理解一下数据本地化的概念,以及什么 MapReduce 数据本地化。
Hadoop 主要的缺点是跨交换网络传输巨量的数据。为了克服这个缺点,Hadoop 提出了数据本地化概念。数据本地化的指的是把计算移动到尽可能离数据近的地方执行,因为移动计算比移动巨量数据要更高效,它可以降低网络开销,增加系统的整体吞吐量。
在 Hadoop 中,数据集是存储在 HDFS 的。而数据集会被切割成很多块,这些块会被存储在 Hadoop 集群的不同节点。在执行 MapReduce 作业的时候,NameNode 把这些 MapReduce 程序的代码发送给与该程序代码将要处理的数据所在 的 datanode 上。这个过程可以结合下面的图来理解。
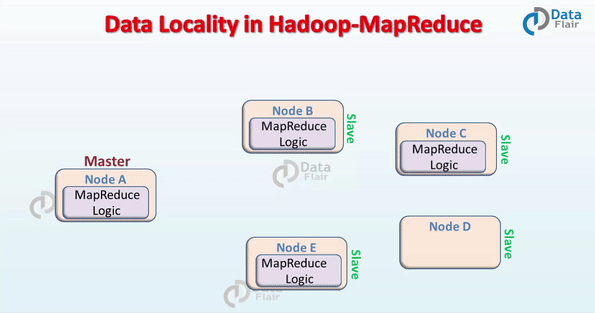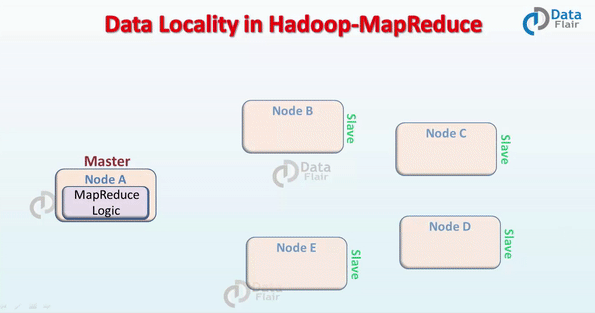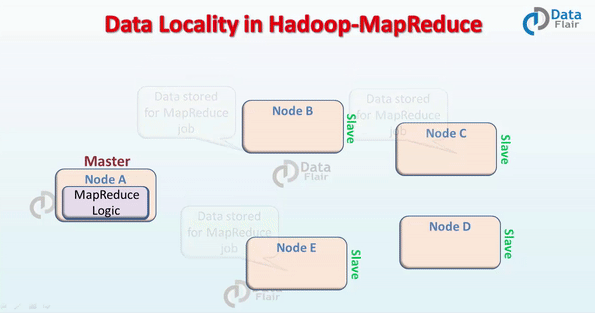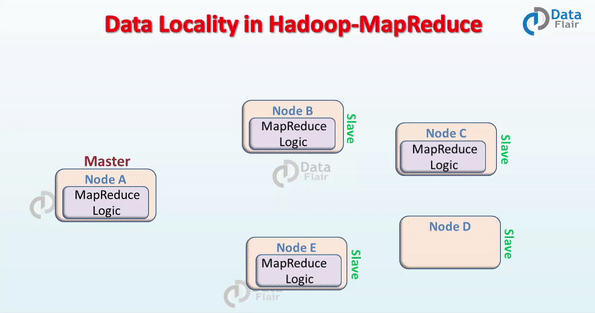
MapReduce 数据本地化的要求
为了达到数据本地化的所有优势,系统架构需要满足下面的条件:
- 首先,集群应该具备合理的拓扑结构。Hadoop 代码必须具有读取数据位置的能力。
- 其次,Hadoop 必须对集群内执行任务的节点的拓扑结构具有感知能力。而且 Hadoop 必须知道数据存储的具体位置。

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











